Empirical Risk and Cross-Entropy in MicroTorch
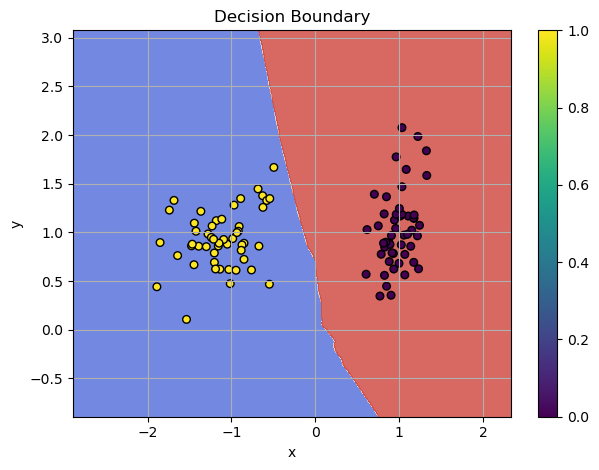
In the previous chapter we prepared the MicroTorch - Deep Learning from Scratch. Now, it's time to dive into creating the loss functions that will guide our model during training. In this session, we're going to focus on building two fundamental loss functions: Binary Cross-Entropy (BCE) and Cross-Entropy (CE), using the Microtorch framework. These functions are essential for training models, especially for classification tasks, and I'll walk you through how to implement them from scratch.

Medieval loss discovery